Sometimes ago, I made an app which simulates a Pokemon game. For this application, I made a predictive model to predict which Pokemon will win based on the data that I have. However, that was not the main thing. In order to create this app, I did a lot of web scraping to get the type, the image or the gif of each Pokemon. Hopefully, through this Pokemon example, you can learn a bit about web scraping.
The link for my Pokemon app can be found here
Packages
Let's start with the package that we need. The 3 main packages that we need will be requests, BeautifulSoup and re.
requests: This package is the most downloaded package of all time. It simplifies the process of making HTTP requests, so that we do not need to manually add query strings to your URLs, or to form-encode your POST data.BeautifulSoup: FYI, this package has nothing to do with being beautiful and soup :)). It helps us to pull data out of HTML and XML files by navigating, searching, and modifying the parse tree. This is the package that will save us a tremendous amount of time.re: This package provides regular expression matching operations similar to those found in Perl. It will help us to find certain words that we want. If you do not have any experiences with this, you can check the link here
import requests
from bs4 import BeautifulSoup
import re
import pandas as pd
Let's the fun begin !!!
I am going to webscrap everything from https://bulbapedia.bulbagarden.net/wiki/. If you are a Pokemon lover, I am sure you will know about it.
In order to get access to any website, we need to use requests package.
url = "https://bulbapedia.bulbagarden.net/wiki/"
response = requests.get(url)
response
<Response [200]>
If you see Response [200] like the one above, it means that you have successfully get inside the website.
After getting in the website, we are going to extract the content of the website by using BeautifulSoup. The content of the website is actually a bunch of HTML/CSS codes that we see when we right click and then inspect the website.
soup = BeautifulSoup(response.text)
soup.prettify
Assuming we have a list of Pokemon name (Pikachu, Bulbasaur, Mew, .....). Each of these Pokemon will have its own page on Bulbapedia. For example, our favourite Pikachu page will be https://bulbapedia.bulbagarden.net/wiki/Pikachu_(Pokémon), while Mew page will be https://bulbapedia.bulbagarden.net/wiki/Mew_(Pokémon). In order to get the data of these Pokemon, we need to actually get into their page and get it.

name = 'Pikachu'
# url + name + "_(Pokémon)" is actually "https://bulbapedia.bulbagarden.net/wiki/" + "Pikachu" + "_(Pokémon)" in this case
response = requests.get(url + name + "_(Pokémon)")
soup = BeautifulSoup(response.text)
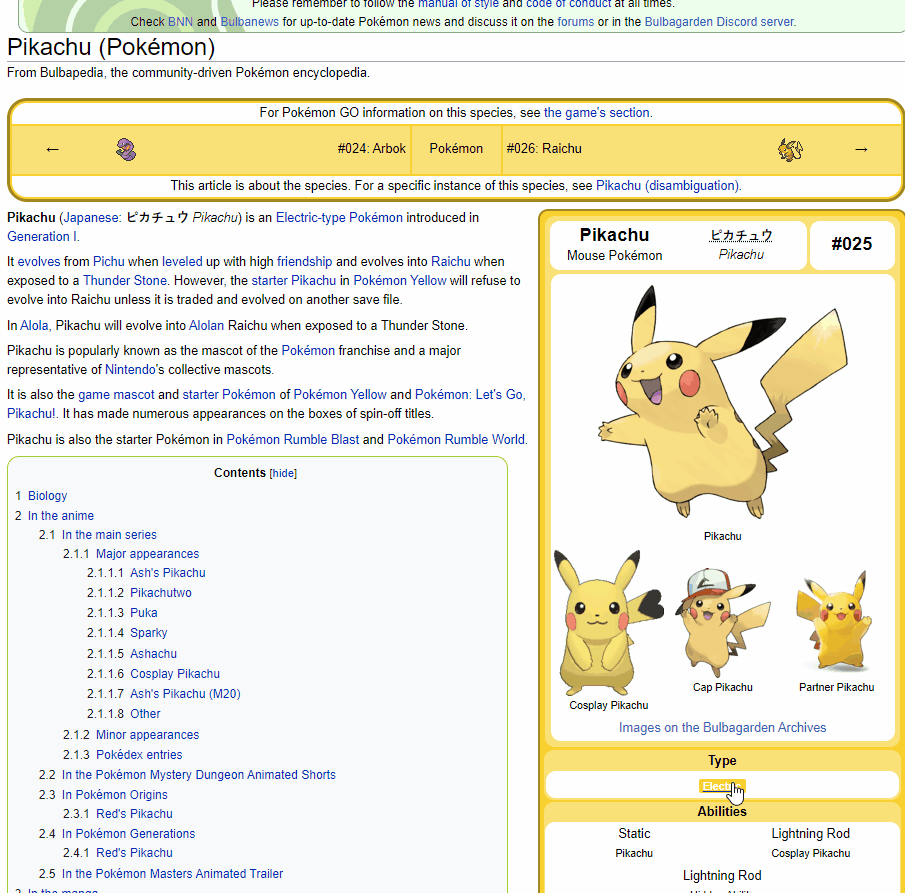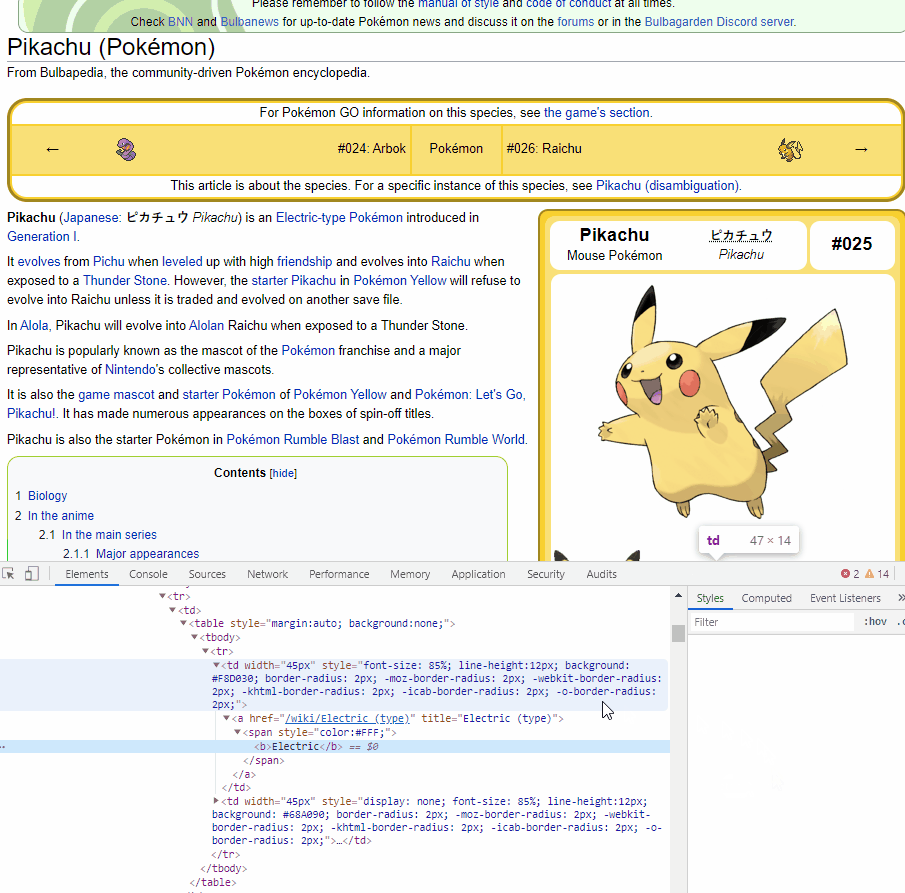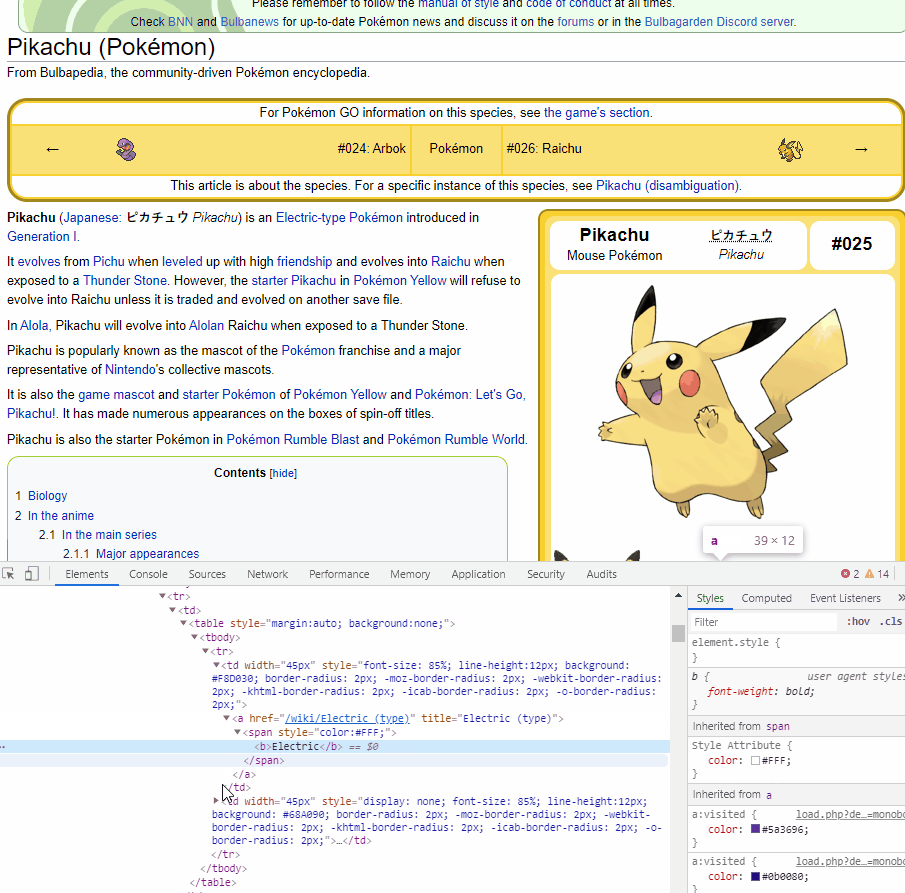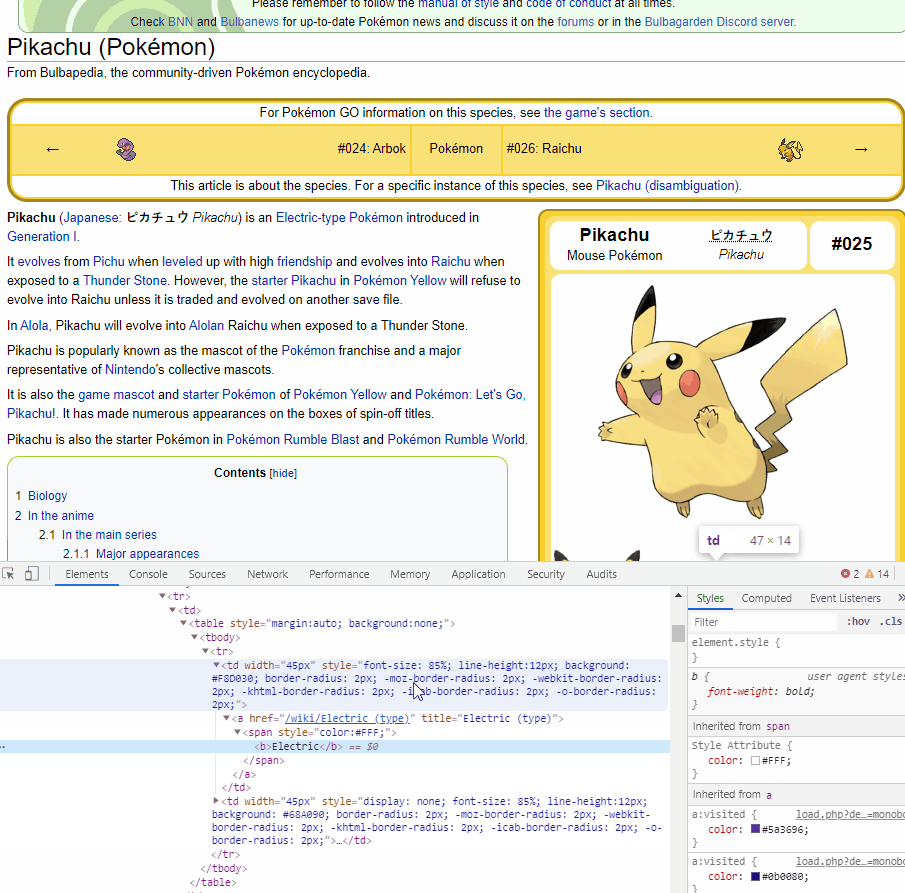
Let's try to get the type of Pikachu. As we can see, information of the type is within a tag, with the title includes (type). We will use find_all to look for a tag including title that has the word (type).
soup.find_all("a", title = re.compile("(type)"))
[<a href="/wiki/Electric_(type)" title="Electric (type)"><span style="color:#FFF;"><b>Electric</b></span></a>,
<a class="mw-redirect" href="/wiki/Unknown_(type)" title="Unknown (type)"><span style="color:#FFF;"><b>Unknown</b></span></a>,
<a class="mw-redirect" href="/wiki/Unknown_(type)" title="Unknown (type)"><span style="color:#FFF;"><b>Unknown</b></span></a>, ...]
We will get a list of a tag following the criteria. Our type information will be always the first one.
poke_type = soup.find_all("a", title = re.compile("(type)"))[0].text
poke_type
'Electric'
Let's do the same thing to get Pikachu image. This time, the source of the image is within alt tag containing name of the Pokemon. There will be multiple images of Pikachu within that page; hence, we are going to only get the first one. Also, the link for Pikachu image is within src tag.
img = soup.find_all("img", alt = re.compile(name))[0]["src"].replace("//","https://")
img
'https://cdn.bulbagarden.net/upload/thumb/0/0d/025Pikachu.png/250px-025Pikachu.png'
You can try to get Pokemon gif, front image, or back image by yourself. I have included the code below. The ending result will be a dictionary including all information of the Pokemon.
characters = []
for name in pokemon_name:
response = requests.get(url + name + "_(Pokémon)")
soup = BeautifulSoup(response.text)
poke_type = soup.find_all("a", title = re.compile("(type)"))[0]["title"].replace(" (type)","")
img = soup.find_all("img", alt = re.compile(name))[0]["src"].replace("//","https://")
gif = soup.find_all("img", src = re.compile("//cdn.bulbagarden.net/upload/"), width = 96)
all_gif = []
for i in range(0, len(gif)):
try:
soup.find_all("img", src = re.compile("//cdn.bulbagarden.net/upload/"), width = 96)[i]["srcset"]
except :
all_gif.append(soup.find_all("img", src = re.compile("//cdn.bulbagarden.net/upload/"), width = 96)[i])
try:
front = all_gif[0]["src"].replace("//","https://")
back = all_gif[1]["src"].replace("//","https://")
except:
print(name)
characters.append({"name" : name.lower(),
"type" : poke_type.lower(),
"img" : {"default" : img,
"front" : front,
"back" : back}
})
characters
[{'name': 'bulbasaur',
'type': 'grass',
'img': {'default': 'https://cdn.bulbagarden.net/upload/thumb/2/21/001Bulbasaur.png/250px-001Bulbasaur.png',
'front': 'https://cdn.bulbagarden.net/upload/7/76/Spr_5b_001.png',
'back': 'https://cdn.bulbagarden.net/upload/e/e9/Spr_b_5b_001.png'}},
{'name': 'ivysaur',
'type': 'grass',
'img': {'default': 'https://cdn.bulbagarden.net/upload/thumb/7/73/002Ivysaur.png/250px-002Ivysaur.png',
'front': 'https://cdn.bulbagarden.net/upload/e/e1/Spr_5b_002.png',
'back': 'https://cdn.bulbagarden.net/upload/0/06/Spr_b_5b_002.png'}},
{'name': 'venusaur',
'type': 'grass',
'img': {'default': 'https://cdn.bulbagarden.net/upload/thumb/a/ae/003Venusaur.png/250px-003Venusaur.png',
'front': 'https://cdn.bulbagarden.net/upload/6/68/Spr_5b_003_m.png',
'back': 'https://cdn.bulbagarden.net/upload/4/47/Spr_b_5b_003_m.png'}},
{'name': 'charmander',
'type': 'fire',
'img': {'default': 'https://cdn.bulbagarden.net/upload/thumb/7/73/004Charmander.png/250px-004Charmander.png',
'front': 'https://cdn.bulbagarden.net/upload/0/0a/Spr_5b_004.png',
'back': 'https://cdn.bulbagarden.net/upload/5/54/Spr_b_5b_004.png'}}, ... }